
Table of Contents
Machine Learning and Data Science
For an overview of the Machine Learning methods, techniques, and technologies we use, see “Machine Learning Methods” page.
Case Studies
Personalized Pagerank Score for Personalized Search
(Graph Processing Framework and Development of Random Walk based Search Tool)
Tools & Frameworks
- Internal Google frameworks (GFS, MapReduce, BigTable, ProtoBuffs)
Languages
- Java, C++, Python..
Description
Many of today’s computational tasks can be structured as graphs and the dynamics of many real-world complex systems can be modeled as graphs. At Google our data of the world wide web naturally fall into this structure, however, the preexisting computation framework MapReduce was not directly suited to large scale path and iterative algorithms and often lead to sub-optimal performance. We built a vertex centric graph processing framework that would be optimized to support computation on billion node, trillion edge static directed graphs.
Pregel was built to keep vertices and edges on the machine that performs the computation and uses network transfers only for messages. We then extended the vertex computations that support algorithmic modeling of topological statistics. PageRank, Betweenness, Eccentricity, Eigenvectors, Recommendations, Spreading Activation. The Pregel style of computation on graphs. also known as “Think like a vertex” has influenced many open source versions such as Apache Giraph, Spark GraphX, Graphlab, Flink Gelly, Powergraph, and more.
One application we built on top of Pregel was a set of algorithms that the importance of a node using personalized page rank techniques. For example in web search we can create a distribution with equal probability mass on the web pages the searching user has frequently visited. These ranks can then be used for both personalized search, recommendation systems, ad serving, and more. . Continued work occurred applying these techniques to social network’s for detect local and global influencers, along with how information cascades through local communities.
Convectively-Induced Turbulence Prediction for Airlines
Tools & Frameworks
- Hadoop (HDFS, Cassandra, Zookeeper, Scalding)
- Spark (fast and general engine for large-scale data processing),
- Mahout (Distributed ML library for Hadoop)
- Scikit-Learn, Numpy, Scipy, ipython (python libraries for prototypes)
- JBLAS (Linear Algebra Library)
- Apache Storm (real-time processing engine)
- Internal Java based data sketching library
Languages
- Scala, Java (production code)
- Python (research code)
Description
Between 50-60% of in air turbulence accidents occur by CIT, our task was to build a machine learning system that would provide forecasts to both local airport control centers and the Federal Aviation Administration. In order to accommodate both the unique characteristics of the domain we had to model, most importantly the spatial and time features; we extended the classical random forest algorithms (Introduced by Breiman) and extend them with a form of relational probability trees to handle spatially and temporally varied data.
This approach gave us the ability to built out a robust our models on a robust data processing engine. A balance between tree brittleness solved by random forests, however, interoperability becomes a challenge as the forest grows. In order to accommodate the domain expert scientists we developed tools for importance analysis.
For this problem we built the algorithms and leveraged large scale data processing frameworks. The production code was written in Scala/Java and the research code was written in Python.
Unsupervised creation of light ontologies as a basis for a search engine
Tools & Frameworks
- AWS
- SPARK (map-reduce algorithms)
- Bespoke algorithms (Java)
Languages
- Python (web spyder)
- Javascript
- Java (algorithms)
Description
Most of the current practical search engines have as one of their main ingredients inverted indexing methodologies. The score for the words in documents based on those indexes are usually defined as terms co-occurrence as a definition of the class that the document belongs to and the analysis of the documents connections through hypertext. Those kind of clustering methodologies tend to record poorly the context and the semantic connections of documents grouped together.
We decided to apply a different approach that would ensure including the context in every document: using light ontologies and terms co-occurrence to limit ambiguity on the terms that define a text by extracting the concepts in the text.
The problem with creating a system based on ontology clustering is that there is no universal validated pre-existing ontology set for every subject on the internet. The task of creating such a set through a supervised methodology is impossible without almost infinite resources.
In the diveling project we used two tactics to breakdown the problem. First we created a set of algorithms that allow to extract the terms that define concepts in a texts’ corpora and create a graph of those terms based on the semantic proximity of those terms within that concept.
Effectively creating light ontologies. Second we implemented a web spider that would create theme based corpora from documents on the web.
The algorithms were custom written in Java and the web spyder was implemented in Python. The map-reduce analysis algorithm to process the web document sets was implemented with SPARK.
Algorithmic Trading
Tools & Frameworks
- .Net
- SLQ Server
Languages
- C#
Types
- Market micro-structures: Low Latency, High-Frequency Trading (HFT/sub 1ms) / Order placement optimisation, transaction cost reduction (friction).
- Statistical Arbitrage: Statistical arbitrage of correlation divergences between different asset class, as well as between assets within a same class.
- Technical Analysis (charting): Time series analysis together with their properties: mostly statistical moments, chart indicators, RSI, MACD, etc…
- Pattern Recognition: Analysis of quasi repetitive time-frame dependent patterns in markets. Use of Neural networks, Machine Learning, Artificial Intelligence such as form recognition. Automated probabilistic learning, particularly Bayesian / Regression, Non-Linear Optimization.
Knowledge
Statistics / Probabilities (Stochastic Methods)
- Arbitrage
- Risk management
- Pricing issues
Courbe de charge pour des sites B2B (2014)
Competition Datascience.net BearingPoint, Challenge GDF Suez (2014)
Description
En 2014 nous avons été habilités par BearingPoint sur une problématique de courbe de charge pour des sites B2B. BearingPoint sont arrivés 23 ème sur 284 participants et nous sommes arrivés dans les 5 premiers avec uniquement 1 contribution.
Voici en quelques lignes un descriptif de la méthode que nous avons utilisée pour atteindre ce résultat:
- Intégration de la non homogénéité temporelle des données: division par jour et par site. Identification des divers facteurs influençant les courbes de charges des 43 sites.
- Examen des données site par site afin de déterminer les meilleures techniques pour prédire les dix prochains jours par période de 10 minutes soit 1440 points par site.
- Critères retenus comme pertinents:
- Mois de l’année
- Jour de la semaine
- Effet week-end
- Calendrier des vacances et jours fériés (lunaire et solaire)
- Régime de Charge: Peak / Off-Peak Heure et minute de la journée
- “Type” de Site (Code NAF)
- Température absolue et relative
- Création de variables explicatives et interpolation spline Cubique des données de température pour correspondre à la périodicité des courbes de charge. “Smoothing” des données de courbes de charges (Savitsky-Golay) et winsorisation des données afin de réduire le bruit des données pour éviter l’erreur de biais.
- Méthodes
Nous avons utilisé 4 méthodes d’analyse prédictive après avoir scindé la base de données fournie en fonction des jours de la semaine et des sites. Ainsi, nous n’avons pas privilégié l’approche globale mais nous avons effectué un apprentissage par site et par jour de la semaine (Lu,Ma,Me,Je,Ve,Sa,Di). Autrement dit, nous n’apprenons que sur les lundis du site n pour prédire le lundi du site n.Pour chaque jour de prédiction nous avons choisi, selon le critère de “scoring” fourni, le modèle minimisant l’erreur de prédiction sur un échantillon de validation parmi les modèles suivants:- Random Forest.
- Régression en réseau de neurone simple.
- Régression de réseau de neurones après application d’un apprentissage non-supervisé sur le temps (mois et heure/minute) et température.
- Support Vector Regression (Radial Basis Function). Utilisation d’une heuristique de recherche simple et “sparse” sur les hyper-paramètres C et Gamma.Au préalable, pour certains sites atypiques ayant très peu de données ou des vacances dans la période de prédiction ou des données de températures anormales sur la période de prédiction nous avons effectué des recherches de paramètres plus poussées en moyennant et cross-validant sur plus d’échantillons.
Conclusion
Notre approche ensembliste regroupant des techniques d’apprentissage supervisé et non-supervisé fut la bonne permettant de mieux prendre en compte les problèmes de de retard entre les variations des courbes de charges et les variations de températures, réduisant ainsi l’erreur de prédiction.
Détection d’anomalies sur des données mixtes marine et de géolocalisation (A.I.S.). 2015
Description
En 2015, nous avons travaillé sur une problématique de détection d’anomalies (navires suspects) à partir de données caractéristiques des vaisseaux et de données de Géolocalisation asynchrones provenant directement des balises A.I.S. présentent sur chaque navire de plus de 300 tonneaux.
Cartographie des navires par clusters (195,000 au total)
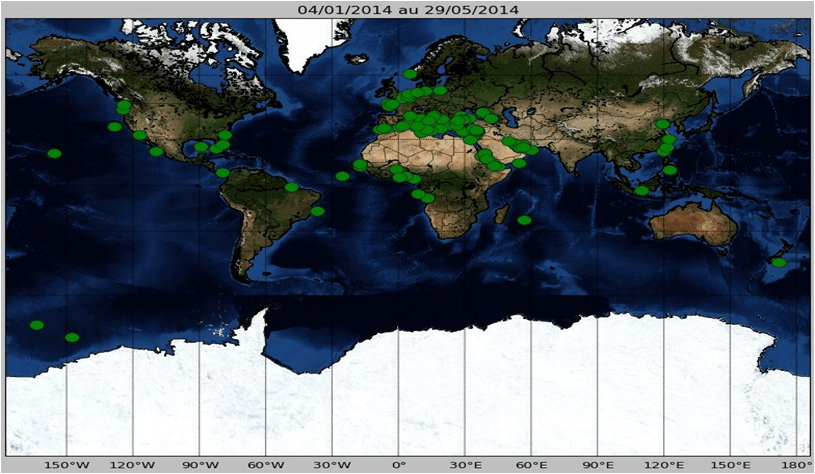
Le résultat étant l’analyse des trajectoires des navires en utilisant un système ensembliste de règles permettant de probabiliser l’activité suspecte des certains navires en temps réel.
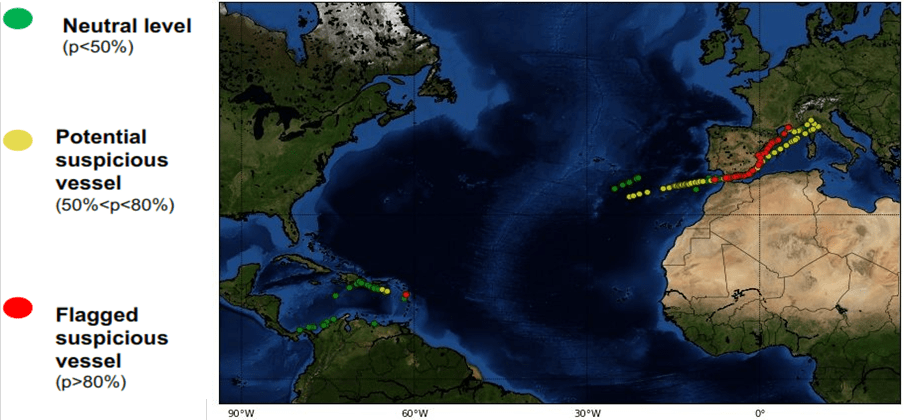
Détection de Fraude dans le domaine de l’assurance (2016)
Description
Presque toutes les machines techniques d’apprentissage ont été utilisés dans la détection de la fraude: SVM, Neural Networks, Clustering, théorie algorithme de recherche locale, la topologie théorie des graphes et enfin, l’analyse de réseau.
Caractéristiques d’un problème de détection de la fraude:
- Grand déséquilibre de classe
- Détection de fraude est semblable à la détection d’anomalies
- Détecter une valeur aberrante dans un groupe
- Détection d’un changement de comportement (en soi)
- Modèles de temps en évolution (fraudeurs évoluent et adaptent si elle est découverte ou si des lacunes sont fermés)
- Connectivité entre les fraudeurs (anneau, points faibles internes, complices)
Dans le graphique, nous recherchons des structures cachées à travers le connexions:
Notre Solution: Factorisation sparse de la structure sous-jacente du graphe (matrice d’adjacence) couplée avec un algorithme de règles agglomerative (apprentissage supervisé).